[ad_1]
Something to look forward to: AMD has published its first patent on chiplet GPU designs. In typical AMD fashion, they’re trying to not rock the boat. Chiplet GPUs are just beginning to emerge. Intel has been forthright about their development process and confirmed the employment of chiplets in their first-generation discrete GPUs. Nvidia, while coy about specifics, have published numerous research papers on the topic. AMD was the last holdout – which only adds to the intrigue.
Chiplets, as the name suggests, are smaller less complex chips, that meant to work together into more powerful processors. They’re arguably the inevitable future for all high-performance components, and, in some cases, the successful present; AMD’s use of chiplet CPU designs has been brilliant.
In the new patent dated December 31, AMD outlines a chiplet design fashioned to mimic a monolithic design as closely as possible. Their hypothetical model uses two chiplets connected by a high-speed inactive interposer called a crosslink.
A crosslink connection sits between the L2 cache and L3 cache on the memory hierarchy. Everything beneath it, such as the cores and L1 cache and L2 cache, are aware of their separation from the other chiplet. Everything above, including the L3 cache and GDDR memory, are shared between the chiplets.
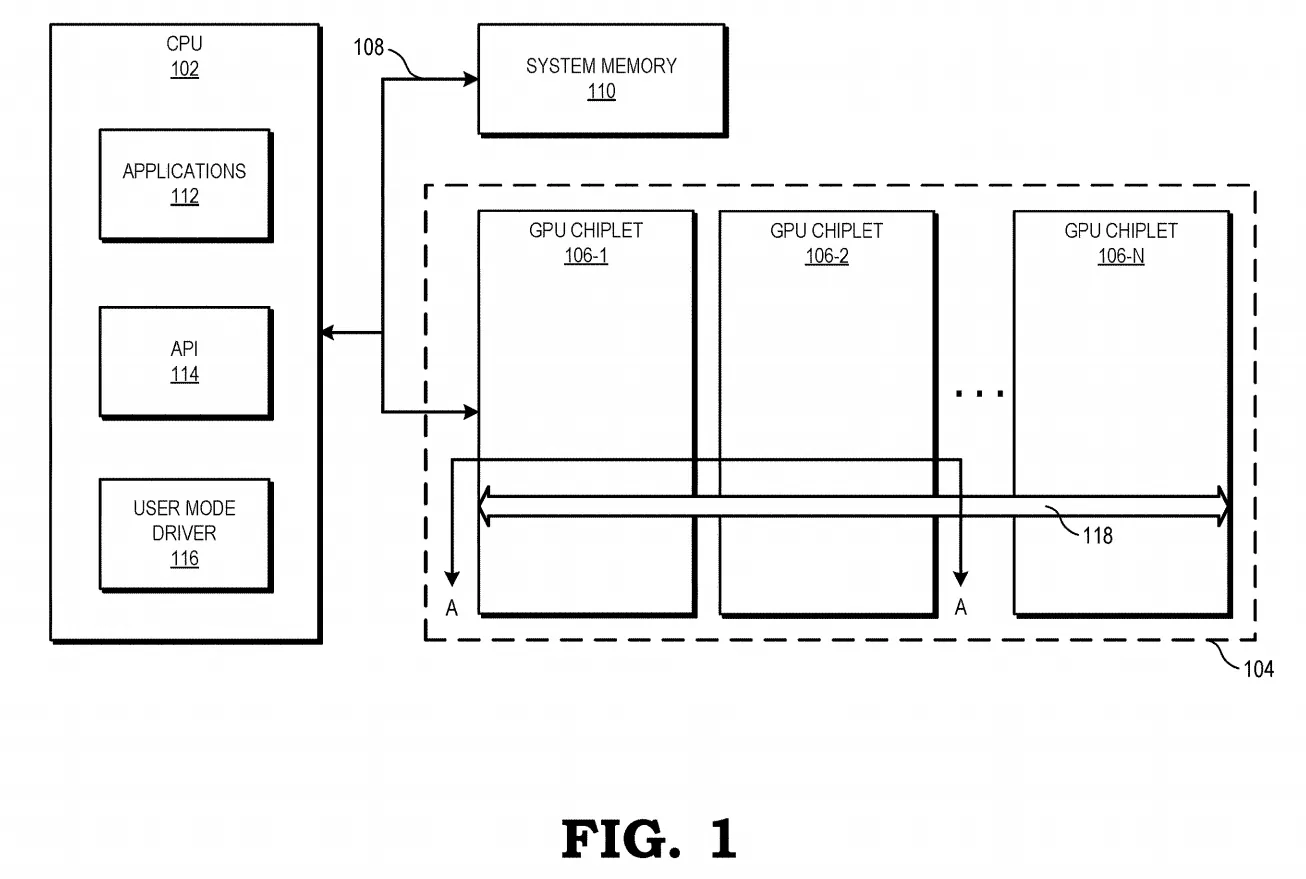
This design is beneficial because it is conventional. AMD claims that compute units can access low-level cache on other chiplets almost as fast as they can access local low-level cache. Should that prove true, software won’t need updating.
The same cannot be said of Intel and Nvidia’s designs. Intel intends on using two new technologies, EMIB (embedded multi-die interconnect bridge) and Foveros. The latter is an active interposer that uses through-silicon-vias, something AMD explicitly states they will not use. Intel’s design lets the GPU house a system-accessible cache that powers a new memory fabric.
Nvidia has not disclosed everything, but have indicated a few directions they might pursue. A research paper from 2017 describes a four-chiplet design and a NUMA (non-uniform memory access) aware and locality aware architecture. It also experiments with a new L1.5 cache, which exclusively holds remote data accesses and is bypassed during local memory accesses.
AMD’s approach might sound the least imaginative, but it also sounds practical. And if history has proven anything, it’s that developer-friendliness is a huge advantage.
Below are additional diagrams from the patent.
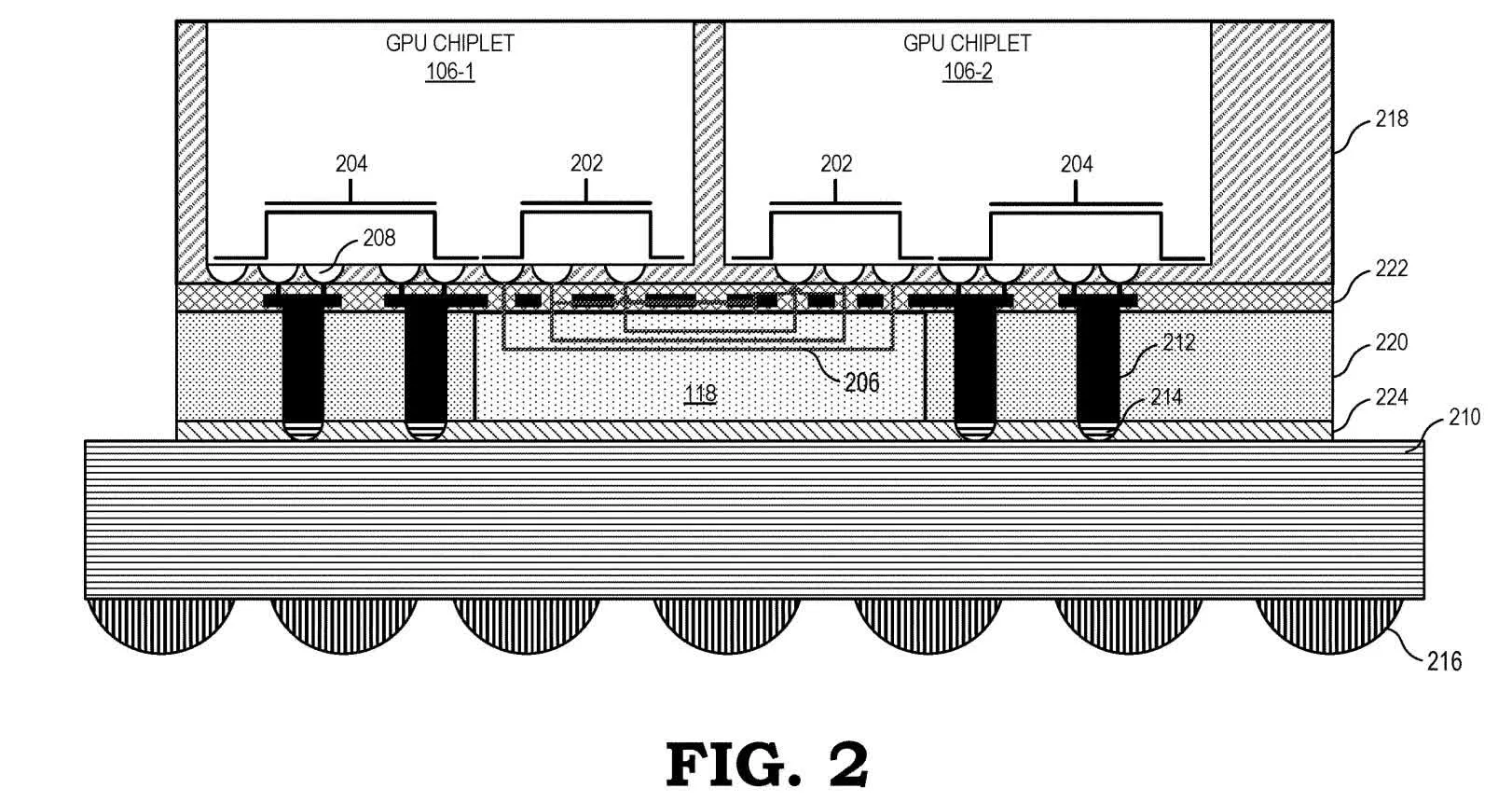
Figure 2 is a cross-sectional view that descends from two chiplets to the circuit board. The two chiplets (106-1 and 106-2) are stacked vertically on the passive crosslink (118) and use dedicated conductor structures to access the crosslink’s traces (206) and subsequently communicate with each other. Conductor structures not attached to the crosslink (204) connect to the circuit board for power and other signaling.
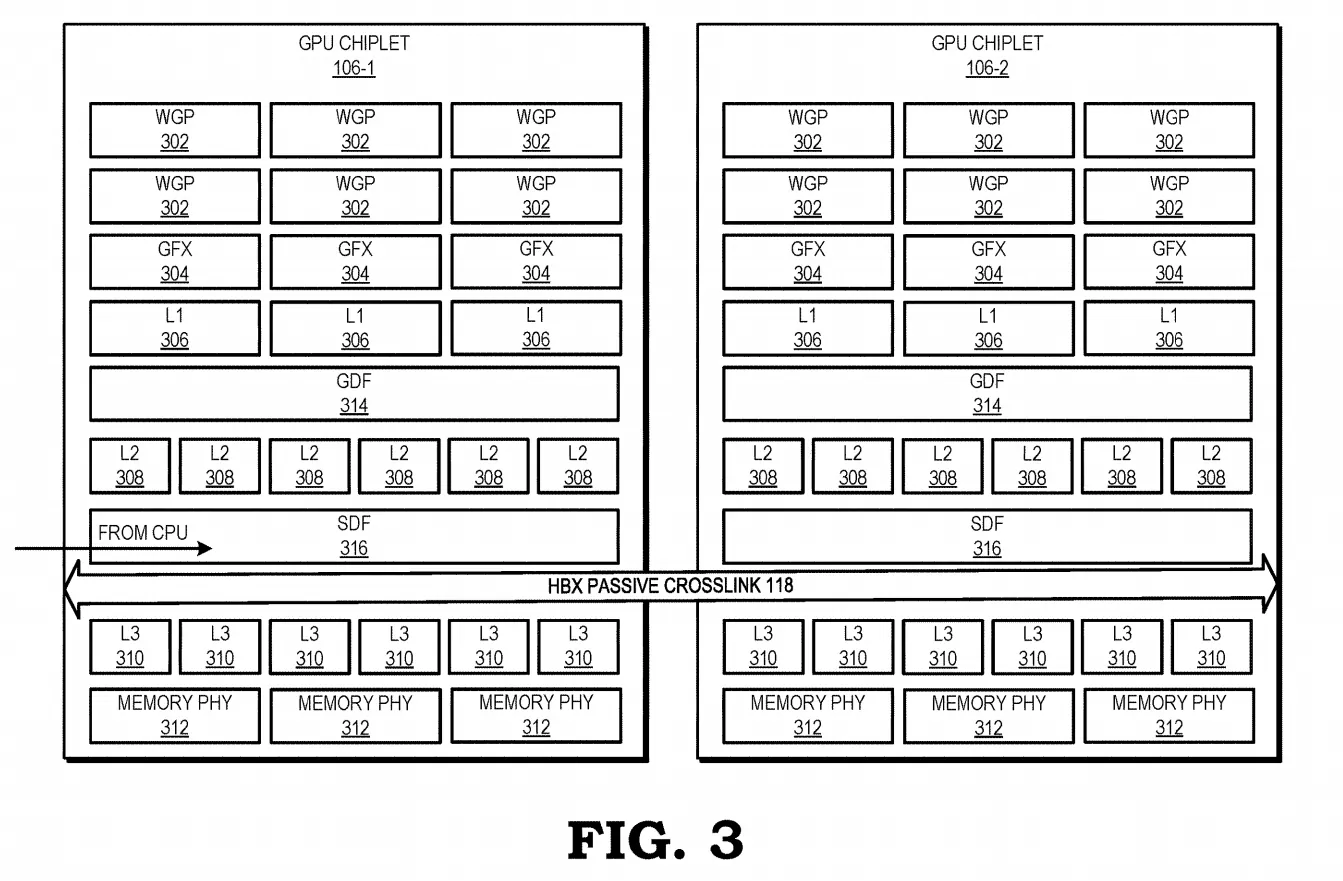
Figure 3 depicts the cache hierarchy. WGPs (work group processors) (302), which are collections of shader cores, and GFXs (fixed function units) (304), which are dedicated processors for singular purposes, connect directly to a channel’s L1 cache (306). Each chiplet contains multiple L2 cache (308) banks that are individually addressable, and also coherent within a single chiplet. Each chiplet also contains multiple L3 cache (310) cache banks that are coherent across the whole GPU.
The GDF (graphics data fabric) (314) connects the L1 cache banks to the L2 cache banks. The SDF (scalable data fabric) (316) combines the L2 cache banks and connects them to the crosslink (118). The crosslink connects to the SDFs on all the chiplets, as well as the L3 cache banks on all the chiplets. The GDDR memory lanes (written as Memory PHY) (312) connect to L3 cache banks.
As an example, if a WGP on one chiplet required data from a GDDR bank on another chiplet, that data would be sent through to an L3 cache bank, then over the crosslink to an SDF, then to an L2 bank, and finally, through a GDF to an L1 bank.
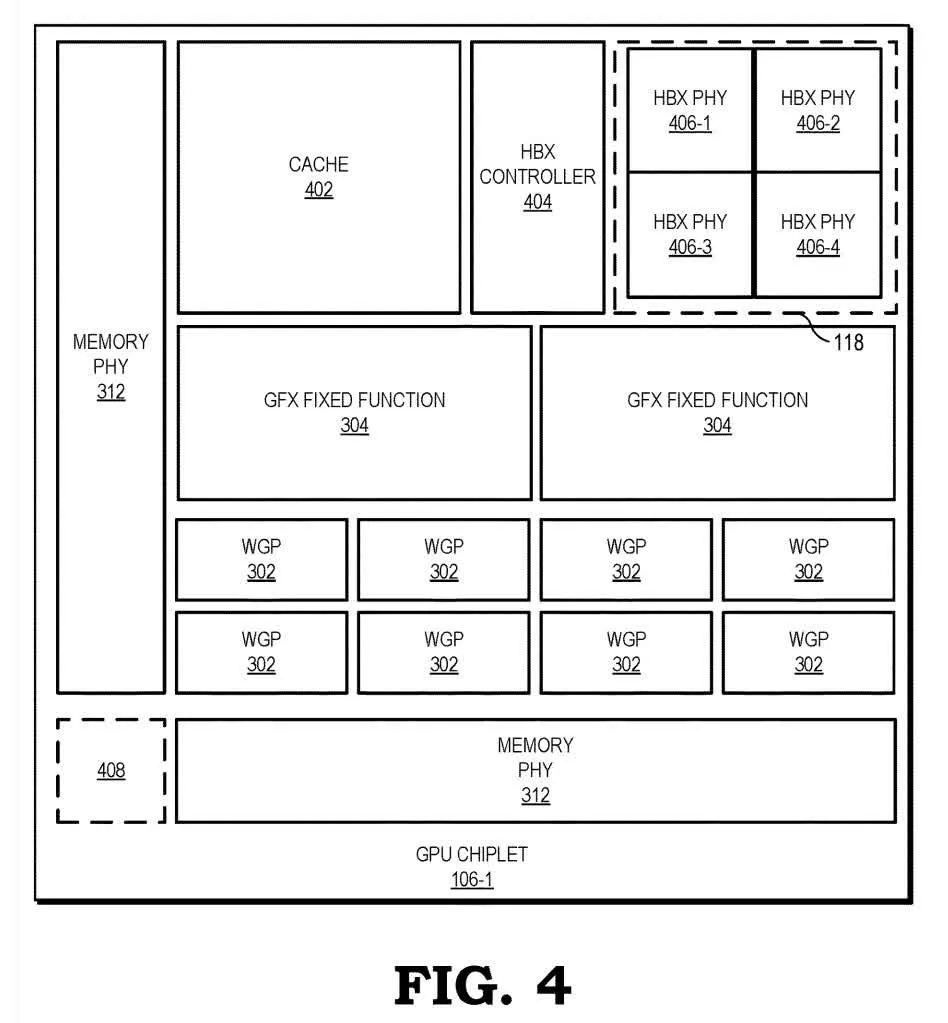
Figure 4 is a bird’s eye view of one chiplet. It shows more accurately the potential locations and scales of various components. The HBX Controller (404) manages the crosslink, which the chiplet is connected to by HBX PHY (406) conductors. The small square in the bottom-left corner (408) is a potential additional connection to the crosslink to connect more chiplets.
[ad_2]
Source link